Jelikož už byla známa potřeba obohatit data o tzv. metadata, vznikaly různé systémy, které se o to snažily. Jen namátkou vybereme např.: tagy, atributy souborového systému, atd. Jsou to však systémy, které navzájem nespolupracují a mají také svá omezení. V případě tagování je problém v tom, že čím více používaný tag je, tím je obecnější (nese méně metainformací).

Kvůli této roztříštěnosti vytvořila organizace W3C pro zachycení sémantické informace objektů a vztahy mezi nimi standard RDF (Resource Description Framework). Obecná definice RDF zní: "jde o obecný rámec pro popis, výměnu a znovupoužití metadat" [RDF]. RDF klade důraz na jednoduchost automatického zpracování webových zdrojů a je proto základním kamenem sémantického webu. Strukturu tohoto frameworku zajišťuje jazyk XML (této reprezentaci se dává zkratka RDF/XML). Samotnou informaci o objektu nám zprostředkovává tzv. tvrzení (anglicky statement), které se skládá z trojice: (ang. triple) subjekt, predikát a objekt[2]. Tato trojice nám naprosto stačí k vyjádření většiny stavů. Např.: Eva (subjekt) mele (predikát) maso (objekt), Marie zná Petra, atd. Je třeba ještě dodat, že objektem může být vedle řetězce znaků (literál) také další zdroj. Webovým zdrojem pak rozumíme každý objekt, kterému je přiřazen jednoznačný identifikátor ve formátu URI. Ten také vedle uzlů v grafu definuje i jeho hrany. Subjekt může být také anonymní (tzv. blank node), který často nese pouze informaci o struktuře a nejspíš se na něj nebude odkazovat
RDF jako datový model sémantického webu se dá nejlépe vyjádřit orientovaným grafem [RDF]. Jednotlivé trojice se pak propojují s dalšími grafy přes společné uzly a vzniká tím jeden velký pavouk.
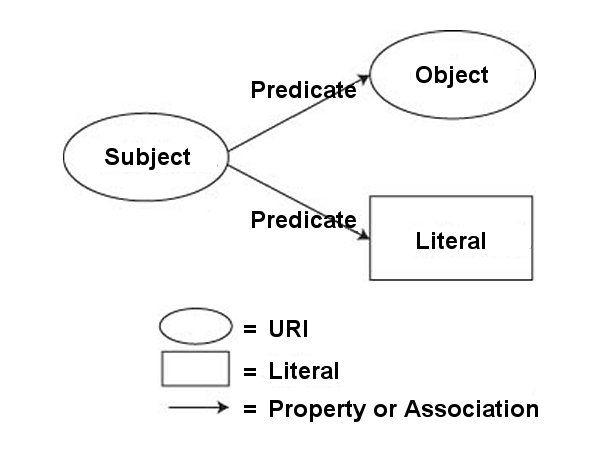
Mezi další možnosti RDF patří: sdružování zdrojů do kolekcí (“container”), reifikace,[3] “typování” zdrojů (rozdělení do tříd) pomocí RDF Schema. [OntologieSvatek]
Jak už jsme uvedli, syntaxe RDF je založena na XML (RDF/XML)[4], což dobře vidíme níže '3.5 - Ukázka RDF'. Element rdf:RDF
ohraničuje oblast popisu jazykem RDF. V tomto elementu také definujeme jmenné
prostory, díky kterým se zkrátí zápis URI identifikátorů na pouhé prefixy
(rdf, vcard, dc). Pro RDF tvrzení je
používán element rdf:Description, subjekt tvrzení je určen atributem rdf:about. RDF
vlastnosti jsou zaznamenány pomocí elementů vložených v elementu rdf:description
(např.: dc:title, vcard:email). Na ukázce kódu RDF si můžeme všimnout, že není
zrovna jednoduchý pro zápis. A proto původní představa, že bude RDF vytvářeno
uživateli ve velkém měřítku, už dávno neplatí. RDF se dnes používá spíše jako
exportní formát, pokud chceme usnadnit zpracování, propojení a odvozování informací
[SemWebKosek].
Příklad 3.5. Ukázka kódu RDF. (Zdroj: [semMuni])
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns\#"
xmlns:vcard="http://www.imc.org/vcard/3.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description about="http://www.sport.cz/fotbal/2003/12/04/spartachelsea.html">
<dc:Title>Sparta Chelsea 0:1</dc:Title>
<dc:creator rdf:resource="http://www.sport.cz/authors/PetrMatulik"/>
<dc:date>2003-12-04</dc:date>
</rdf:Description>
<rdf:Description about="http://www.sport.cz/authors/PetrMatulik">
<vcard:fn>Petr Matulík</vcard:fn>
<vcard:email>petramatulik@email.cz</vcard:email>
</rdf:Description>
</rdf:RDF>
RDF jako formát, se používá také v nejednom z programů. Jedním z takových
programů, je Mozilla. Ta používá RDF pro ukládání informaci o uživateli (jeho
profil). Firma Hewlett-Packard zase pro změnu vyvíjí knihovnu Jena, která slouží pro
práci s RDF v jazyce Java [SemWebVavra].
SPARQL (Simple Protocol And RDF Query Language) je primárně dotazovací jazyk, který je určený k manipulaci s RDF databázemi a k tvoření dotazů nad RDF grafy. Jednoduše řečeno, SPARQL nám umožňuje z ontologií získávat informace, které hledáme za pomocí sofistikovaných dotazů. Je nástupcem několika dotazovacích jazyků, např. RDF Query Language, RDQL, které jsou rovněž založeny na datech RDF. SPARQL je standardem W3C a jeho syntaxe je podobná klasickému SQL [sparql].
Dotaz ve SPARQLu se skládá ze 3 částí:
-
PREFIX - používá se k selekci jmenného prostoru (namespace)
-
SELECT - používá se k definování zobrazovacího formátu
-
WHERE - používá se pro formulování aktuálního dotazu.
Vyhledané výsledky mohou být dodatečně vytříděny pomocí příkazu SORT BY a použitím čísla OFFSET mohou být omezeny do specifického čísla předmětu [ChipSemWeb].
SPARQL však není jediným používaným dotazovacím jazykem nad RDF. V komentářích pod článkem o sémantickém webu se strhla diskuze, zda je SPARQL dostatečně inteligentní a dostačující pro práci s daty uloženými v RDF. Nám bude stačit, že víme o možnosti, jak jednoduše dostat data z RDF zápisu. Jen pro úplnost si zde uvedeme další dotazovací jazyky: SeRQL, TRIPLE, XSPARQL, Versa, Xcerpt či Tequila [uvodSemWeb].
[2] Často se setkáváme také s jiným názvoslovím: podmět, přísudek a předmět nebo zdroj, vlastnost a hodnota vlastnosti.
[3] Možnost formulovat tvrzení o tvrzeních, zachycení relací o vyšší aritě (např. odlišení “hlavní” hodnoty)
[4] Je však důležité upozornit, že jsou přípustné i jiné reprezentace RDF, které nejsou založené na XML [SemanticWeb].